Реализация базовых типов в CPython
Типизация в python
Статическая типизация предполагает, что программист явным образом определяет тип переменной, который не меняется в процессе выполнения программы. Типы в этом случае проверяются на этапе компиляции, тем самым снижается вероятность появления ошибок.
Все данные в python представлены в виде объектов, а те в свою очередь наследуются от PyObject в реализации CPython. Любой объект ссылается на область памяти. Тип переменной определяется тем, на что указывает в текущий момент времени ссылка. Когда переменная начинает ссылаться на другой объект – ее тип меняется. Это называется динамической типизацией. Python язык с динамической типизацией.
Все типы данных являются объектами и расширяют две базовые структуры PyObject_VAR_HEAD и PyObject_HEAD:
/* Define pointers to support a doubly-linked list of all live heap objects. */
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;
#define PyObject_HEAD PyObject ob_base;
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
PyTypeObject *ob_type;
} PyObject;
#define PyObject_VAR_HEAD PyVarObject ob_base;
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size; /* Number of items in variable part */
} PyVarObject;
PyObject_VAR_HEAD - макрос, который используется для объявления объектов переменной длины. PyObject_HEAD – для обычных объектов.
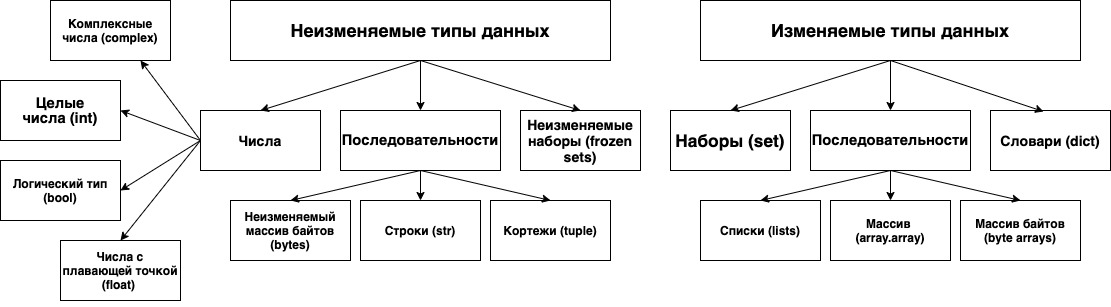
Неизменяемые типы данных
Объект, значение которого остается неизменным после создания, принадлежит к неизменяемым типам. К этим типам относятся:
Числа
Целые числа (int)
Имеют неограниченную длину. Но как же python работает с неограниченными числами? PyLongObject – подтип PyObject, который представляет int в CPython. Он представлен так:
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
В случае с int, ob_digit хранит массив чисел, которые составляют целевое значение, модуль числа ob_size определяет размер ob_digit. Отрицательные числа представлены значениями с ob_size < 0. Таким образом ob_digit может быть расширен до бесконечности и ограничен только размером оперативной памяти.
Обратите внимание что, создавая числа от -5 до 256 включительно, вы фактически возвращаете ссылку на существующий объект, т.к. python хранит этот диапазон чисел в заранее созданном кэше.
#define _PY_NSMALLPOSINTS 257
#define _PY_NSMALLNEGINTS 5
#define NSMALLPOSINTS _PY_NSMALLPOSINTS
#define NSMALLNEGINTS _PY_NSMALLNEGINTS
#define IS_SMALL_INT(ival) (-NSMALLNEGINTS <= (ival) && (ival) < NSMALLPOSINTS)
static PyObject *
get_small_int(sdigit ival)
{
assert(IS_SMALL_INT(ival));
PyInterpreterState *interp = _PyInterpreterState_GET();
PyObject *v = (PyObject*)interp->small_ints[ival + NSMALLNEGINTS];
Py_INCREF(v);
return v;
}
Логический тип (bool)
Данный тип является подтипом целочисленного типа int и определен как Py_False для False объектов и Py_True для True объектов. Интересно, что размер False меньше размера True
False.__sizeof__()
True.__sizeof__()
24
28
Это происходит из того, что False является нулем, представлен как int с ob_size == 0 и не требует двоичных цифр для хранения в памяти.
Числа с плавающей точкой двойной точности (float)
Это вещественные числа, которые занимают в памяти 8байт. Числа одиночной точности не поддерживаются. В CPython реализованы на базе double и представлены следующей структурой:
typedef struct {
PyObject_HEAD
double ob_fval;
} PyFloatObject;
Комплексные числа (complex)
Представленны в виде двух чисел с плавающей точкой. В CPython реализованы в виде двух структур на базе double:
typedef struct {
double real;
double imag;
} Py_complex;
typedef struct {
PyObject_HEAD
Py_complex cval;
} PyComplexObject;
Комплексные числа, это числа вида a+b*i, где a – это действительная часть, а b – мнимая. В Py_complex real и imag представляют действительную и мнимую части соответственно.
Последовательности
Строки (str)
Это неизменяемые последовательности кодов в системе Unicode. Python не поддерживает тип char. Каждый символ в строке сам является строкой длинной 1 символ. В CPython строки представлены тремя структурами.
Строки, для которых на момент создания известны размер (Py_ssize_t size) и максимальный символ (Py_UCS4 maxchar), называются "компактными" объектами. Данные о строке следуют непосредственно за структурой и располагаются в одном блоке памяти. Максимальный символом ASCII – 128, поэтому ASCII строки используют структуру PyASCIIObject и являются «компактными». Прочие «компактные» объекты используют структуру PyCompactUnicodeObject.
typedef struct {
PyObject_HEAD
Py_ssize_t length;
Py_hash_t hash;
struct {
unsigned int interned:2;
unsigned int kind:3;
unsigned int compact:1;
unsigned int ascii:1;
unsigned int ready:1;
unsigned int :24;
} state;
wchar_t *wstr;
} PyASCIIObject;
typedef struct {
PyASCIIObject _base;
Py_ssize_t utf8_length;
char *utf8;
Py_ssize_t wstr_length;
} PyCompactUnicodeObject;
Создание «компактных» объектов происходит посредством функции PyUnicode_New:
PyAPI_FUNC(PyObject*) PyUnicode_New(
Py_ssize_t size, /* Number of code points in the new string */
Py_UCS4 maxchar /* maximum code point value in the string */
);
Устаревшие объекты — это строки, у которых максимальный символ (Py_UCS4 maxchar) заранее не известен. Данные о тексте располагаются отдельно от структуры:
typedef struct {
PyCompactUnicodeObject _base;
union {
void *any;
Py_UCS1 *latin1;
Py_UCS2 *ucs2;
Py_UCS4 *ucs4;
} data; /* Canonical, smallest-form Unicode buffer */
} PyUnicodeObject;
Для создания «устаревших» строк используется функция, которая помечена как deprecated:
Py_DEPRECATED(3.3) PyAPI_FUNC(PyObject*) PyUnicode_FromUnicode(
const Py_UNICODE *u, /* Unicode buffer */
Py_ssize_t size /* size of buffer */
);
Кортежи (tuple)
Кортеж – аналог списка, который нельзя изменить после его создания. Его реализация в CPython представлена структурой PyTupleObject:
typedef struct {
PyObject_VAR_HEAD
/* ob_item contains space for 'ob_size' elements.
Items must normally not be NULL, except during construction when
the tuple is not yet visible outside the function that builds it. */
PyObject *ob_item[1];
} PyTupleObject;
Объект ob_item содержит указатели на объекты кортежа и является статическим массивом, память под который выделяется следующим образом:
PyObject *
PyTuple_New(Py_ssize_t size)
{
PyTupleObject *op;
#if PyTuple_MAXSAVESIZE > 0
if (size == 0) {
return tuple_get_empty();
}
#endif
op = tuple_alloc(size);
if (op == NULL) {
return NULL;
}
for (Py_ssize_t i = 0; i < size; i++) {
op->ob_item[i] = NULL;
}
tuple_gc_track(op);
return (PyObject *) op;
}
Неизменяемый массив байтов (bytes)
bytes – неизменяемая последовательность, элементы которой представляют собой целые числа в диапазоне от 0 до 255 включительно. В CPython bytes представлена структурой PyBytesObject:
typedef struct {
PyObject_VAR_HEAD
Py_hash_t ob_shash;
char ob_sval[1];
/* Invariants:
* ob_sval contains space for 'ob_size+1' elements.
* ob_sval[ob_size] == 0.
* ob_shash is the hash of the string or -1 if not computed yet.
*/
} PyBytesObject;
Байты не являются символами, но они могут кодировать/декодировать строки при помощи кодировок.
Неизменяемые наборы (frozen sets)
Наборы — это неупорядоченная коллекция уникальных хешируемых объектов, которые представлены структурой PySetObject:
typedef struct {
PyObject_HEAD
Py_ssize_t fill; /* Number active and dummy entries*/
Py_ssize_t used; /* Number active entries */
/* The table contains mask + 1 slots, and that's a power of 2.
* We store the mask instead of the size because the mask is more
* frequently needed.
*/
Py_ssize_t mask;
/* The table points to a fixed-size smalltable for small tables
* or to additional malloc'ed memory for bigger tables.
* The table pointer is never NULL which saves us from repeated
* runtime null-tests.
*/
setentry *table;
Py_hash_t hash; /* Only used by frozenset objects */
Py_ssize_t finger; /* Search finger for pop() */
setentry smalltable[PySet_MINSIZE];
PyObject *weakreflist; /* List of weak references */
} PySetObject;
Данная структура используется как для обычных наборов, так и для неизменяемых, однако есть некоторые отличия. Для set значение поля hash равно -1. Frozenset является хешируемым, поэтому hash используется. Элементы самого множества представлены структурой setentry:
typedef struct {
PyObject *key;
Py_hash_t hash;
} setentry;
Изменяемые типы данных
Значения некоторых переменных может изменятся. В этом случае говорят об объектах изменяемых типов.
Последовательности
Списки (lists)
Списки в CPython представлены структурой PyListObject:
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
Как видим, поле ob_item содержит вектор указателей на элементы списка и является динамическим массивом. Поле allocated равно размеру буфера, до которого добавление новых элементов происходит быстро. Как только количество элементов ob_size равно allocated, происходит создание нового массива большей емкости и копирование в него элементов старого массива. Устанавливается новый allocated, больший по отношению к старому. allocated всегда кратен 4, а модель его роста следующая: 0, 4, 8, 16, 24, 32, 40, 52, 64, 76 и т.д.
Массив (array.array)
Array - последовательность однотипных базовых элементов: str, int, float. Тип значений задаётся при инициализации массива. В отличие от списков, массив является однородным в части типов, хранящихся в нем элементов. Из-за того, что данные в структуре хранятся “как есть”, размер массива Python немного меньше размера списка, ведь во втором случае помимо самих значений хранятся ссылки на них.
f_arr = array.array('f', (random() for _ in range(10 ** 7)))
print(f"Float array size: {f_arr.__sizeof__()}")
d_arr = array.array('d', (random() for _ in range(10**7)))
print(f"Double array size: {d_arr.__sizeof__()}")
lst = list(random() for _ in range(10 ** 7))
print(f"Double list size: {lst.__sizeof__()}")
Float array size: 40970208
Double array size: 81940352
Double list size: 87002272
Массивы с CPython представлены следующими структурами:
struct arraydescr {
char typecode;
int itemsize;
PyObject * (*getitem)(struct arrayobject *, Py_ssize_t);
int (*setitem)(struct arrayobject *, Py_ssize_t, PyObject *);
int (*compareitems)(const void *, const void *, Py_ssize_t);
const char *formats;
int is_integer_type;
int is_signed;
};
typedef struct arrayobject {
PyObject_VAR_HEAD
char *ob_item;
Py_ssize_t allocated;
const struct arraydescr *ob_descr;
PyObject *weakreflist; /* List of weak references */
Py_ssize_t ob_exports; /* Number of exported buffers */
} arrayobject;
Вот так реализованы получение и установка элементов массива типа int в python (тип signed char в C):
static PyObject *
b_getitem(arrayobject *ap, Py_ssize_t i)
{
long x = ((signed char *)ap->ob_item)[i];
return PyLong_FromLong(x);
}
static int
b_setitem(arrayobject *ap, Py_ssize_t i, PyObject *v)
{
short x;
/* PyArg_Parse's 'b' formatter is for an unsigned char, therefore
must use the next size up that is signed ('h') and manually do
the overflow checking */
if (!PyArg_Parse(v, "h;array item must be integer", &x))
return -1;
else if (x < -128) {
PyErr_SetString(PyExc_OverflowError,
"signed char is less than minimum");
return -1;
}
else if (x > 127) {
PyErr_SetString(PyExc_OverflowError,
"signed char is greater than maximum");
return -1;
}
if (i >= 0)
((char *)ap->ob_item)[i] = (char)x;
return 0;
}
Массив байтов (byte arrays)
Тип PyByteArrayObject представляет изменяемый массив байтов bytes. В CPython реализован в следующем виде:
typedef struct {
PyObject_VAR_HEAD
Py_ssize_t ob_alloc; /* How many bytes allocated in ob_bytes */
char *ob_bytes; /* Physical backing buffer */
char *ob_start; /* Logical start inside ob_bytes */
Py_ssize_t ob_exports; /* How many buffer exports */
} PyByteArrayObject;
Наборы (set)
В отличие от frozen sets, set является изменяемой структурой данных. Внутренняя реализация такая же как у frozen sets.
Словари (dict)
Словарь – это объект, который хранит список сопоставлений «ключу - значение». В CPython представлен структурой PyDictObject и реализован в виде хеш-таблицы. Если говорить простым языком, хеш-таблица – это массив, индекс которого вычисляется на основе хеш-функции по ключу. Если для разных ключей хеш-функция возвращает одинаковый результат своего выполнения, то говорят о том, что произошла коллизия, поэтому основная задача хеш-функции избегать коллизий и компактно «укладывать» объекты в таблицу.
Рассмотрим таблицу с количеством строк «T», и «N» сопоставлений «ключ - значение», каждый из которых занимает 24 байта. В примитивном виде хеш-таблицу можно представить так:
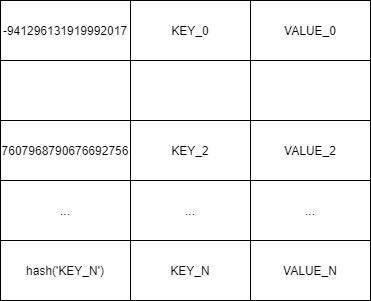
Легко заметить, что в такой реализации таблица является очень разряженной. Например, для hash('a') результат будет 2574896275097747149, т.е. строка с индексом 2574896275097747149 будет занята, а предшествующие ей строки будут свободны. Можно представить хеш-таблицу так:
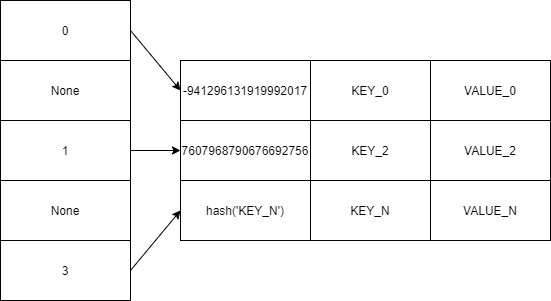
Здесь используются две структуры: список индексов размера «T» и список сопоставлений «ключ - значение» размера «N». Экономия по памяти составляет от 30% до 95% в зависимости от заполненности таблицы в первой реализации, при этом, чем меньше таблица, тем выгода больше. Так размер занимаемой памяти в первом случае:
24 * T
во втором случае
24 * N + sizeof(index) * T
Дополнительным плюсом является более быстрая итерация по таблице в «N» строк, например, для получения списка ключей или значений. Также в случае изменения размера структуры, которая хранит сопоставления «ключ - значение», затрагивается меньшие фрагменты памяти и изменение размера происходит быстрее.
Вернемся к коллизиям и представим, что для ключа «KEY_0» и «KEY_2» хеш функция вернула один результат «1». Можно хранить список значений для одного ключа:
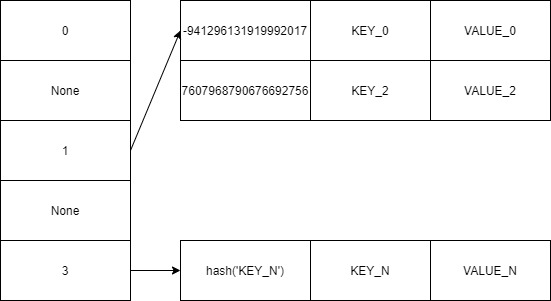
Такой метод разрешения коллизий называется «метод цепочек», однако в python используется алгоритм, известный как «открытая адресация» (реализация доступна в dictobject.c). Алгоритм вставки при возникновении коллизии находит доступную ячейку и вставляет значение в неё. Метод нахождения свободных ячеек называется последовательностью проб, который также имеет свои алгоритмы поиска, такие как линейное или квадратичное пробирования. Линейное пробирование используется в python.
Структура, которая хранит хеш, ключ и значение:
typedef struct {
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictKeyEntry;
Следующая структура представляет собой словарь:
typedef struct {
PyObject_HEAD
Py_ssize_t ma_used;
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
PyObject **ma_values;
} PyDictObject;
Интересно, что на основе значений ma_keys и ma_values выбирается способ хранения данных словаря. Если ma_values равно NULL, то ключи и их значения хранятся в одной структуре в поле ma_keys. Если ma_values заполнено, ключи хранятся в ma_keys, а их значения в ma_values. Таким образом python размещает небольшие словари в одном блоке памяти с фиксированным размером. В случае со средними и большими словарями, для хранения будут использоваться отдельные блоки памяти переменного размера.